- Visualisierungen
Diese Webseite ermöglicht es, im Feld gesammelte und in einer Vegetationstabelle dargestellte ökologische Daten zu visualisieren. Es stehen drei verschiedene Visualisierungsmöglichkeiten (Abb. 1) zur Auswahl: Korrespondenz (Abb. 2), Clustering (Abb. 3) und Ordination (Abb. 4). Dabei geht es um einen raschen Überblick oder Einblick in die Daten und nicht um einen Ersatz für eine statistische Analyse. Da die gesamte Auswertung und Visualisierung der Daten online stattfindet, können nur Daten in kleinerem Umfang (bis zu Matrizen von etwa 50 Zeilen x 50 Spalten) visualisiert werden. Bei grösseren Datenmengen ist bei einigen Visualisierungen mit längeren Rechenzeiten im zwei oder dreistelligen Sekundenbereich zu rechnen.Starten Sie im Normalfall Ihre Visualisierung in der Korrespondenz-Ansicht (Abb. 2). Dabei wird Ihnen Ihre Vegetationstabelle als "Schachbrettmuster" gezeigt, um Ihnen Ihre Daten so darzustellen, wie Sie diese aus Ihrer Vegetationstabelle bereits kennen. Je dunkler ein Feld dargestellt wird, desto grösser ist die Deckung der entsprechenden Art in der entsprechenden Vegetationsaufnahme. Sie können Ihre Daten nun mit Hilfe von Klicks neu oder anders darstellen.
Wenn Sie die Visualisierung Clustering wählen (Abb. 3), werden Ihre Vegetationsaufnahmen in einem ähnlichen Schachbrettmuster dargestellt, wie Sie es schon von der Visualisierung "Korrespondenz" her kennen. Hier werden aber die Distanzen, also die Unterschiede von einer zur anderen Vegetationsaufnahme, in Form des Bray-Curtis-Koeffizient dargestellt. Je dunkler ein Feld, desto grösser der Unterschied zwischen zwei Vegetationsaufnahmen. Das in der Visualisierung "Clustering" vorgenommene Clustering wird im übrigen auch für andere Visualisierungen übernommen. Gleichzeitig ist das Clustering in anderen Visualisierungen nur verfügbar, wenn in der Visualisierung "Clustering" auch ein Clustering gemacht wurde.
In der letzten Visualisierung, der sogenannten Ordination werden die unterschiedlichen Vegetationsaufnahmen auf den zweidimensionalen Raum reduziert (Abb. 4). Dabei gehen Informationen verloren. Das gewählte Ordinationsverfahren ist die sogenannte polare Ordination. In dieser Visualisierung werden die einzelnen Vegetationsaufnahmen als Punkte und die Differenzen zwischen Vegetationsaufnahmen als Distanz dargestellt. Die Clusters werden immer anhand von Farben dargestellt, dies gilt auch für die Ordination.

Abbildung 1: Laden der Daten und Auswahl der Visualisierungen
- Korrespondenz
Die Ansicht "Korrespondenz" (Abb. 2) visualisiert Ihnen Ihre Daten zuerst so, wie Sie diese eingegeben haben. Deshalb starten Sie Ihre Visualisierung normalerweise in dieser Ansicht. Anstelle einer unübersichtlichen Tabelle mit Zahlen erhalten Sie ein schnell erfassbares Schachbrettmuster. Dabei geben die Zeilen immer noch die Arten, die Spalten die Vegetationsaufnahmen wieder. Fahren Sie mit der Maus über das Schachbrett und achten Sie auf die blaue Schrift am linken und oberen Rand des Schachbrettes. Dort werden Ihnen die Namen der Arten und der Vegetationsaufnahmen angezeigt. Die Dunkelheit der einzelnen Quadrate zeigt dabei den Deckungsgrad der jeweiligen Art an: Je dunkler, desto höher die Deckung, d.h. desto dominanter ist die Art in der entsprechenden Vegetationsaufnahme vertreten. Möchten Sie sich die Deckung als genaue Zahl anzeigen lassen, klicken Sie ganz einfach irgendwo auf das Schachbrett: Es wird nicht nur die aktuelle Zeile (Art) und die aktuelle Spalte (Vegetationsaufnahmen) mit blauer Farbe hervorgehoben, sondern auch der Deckungsgrad der Art in der entsprechenden Vegetationsaufnahmen blau auf hellblauem Hintergrund angezeigt. Klicken Sie ein zweites Mal, um die blauen Hervorhebungen wieder verschwinden zu lassen.Die drei Kästchen auf der linken Seite (Abb. 2) ermöglichen Ihnen, Ihre Daten auf unterschiedliche Art und Weise darzustellen. Klicken Sie das erste Kästchen an, "ordnet" die Visualisierung Ihre Daten. Dies ist das aufwändigste Verfahren und beansprucht am meisten Rechenzeit. Haben Sie einen Moment Geduld und klicken Sie auf "weiter", falls Sie vom Browser gefragt werden, ob er das Skript weiter ausführen soll. Das Ordnen der Daten beruht auf einer sogenannten Korrespondenzanalyse. Dabei werden Zeilen (Arten) und Spalten (Vegetationsaufnahmen) abwechslungsweise geordnet, so dass ähnliche (korrespondierende) Arten nahe zueinander zu liegen kommen. Da auch die Spalten geordnet werden, kommen ähnliche Vegetationsaufnahmen ebenfalls nahe zueinander zu liegen. Die Daten werden dabei nicht verändert.
Das zweite Kästchen berechnet den 10er-Logarithmus der Deckungen. Dazu wird zuerst die Zahl 1 zu jedem Deckungsgrad dazugezählt, da der Logarithmus von 0 bekanntlich nicht definiert ist. Nun ist es möglich, jede Deckungszahl zu logarithmieren. In dieser Visualisierung kam der Zehner-Logarithmus zur Anwendung. Genauso gut hätte auch ein anderer Logarithmus verwendet werden können. Der Logarithmus betont die kleineren Werte unter den Deckungszahlen. Für den Botaniker bedeutet dies, dass selten vorkommende Arten stärker gewichtet werden. Dies ist sinnvoll, da meistens wenige Arten dominieren und Unterschiede besser zum Vorschein kommen, wenn seltene Arten hervorgehoben werden. Für die Visualisierung bedeutet dies, dass anfänglich kaum sichtbar eingefärbte Deckungen durch die Logarithmierung einen dunkleren Ton erhalten. Dabei bleibt aber die Reihenfolge der Deckungen natürlich erhalten. Genauso bleibt ein Deckungsgrad von Null Null und die maximale Deckung bleibt die maximale Deckung (allerdings mit einem anderen Wert). Vergleichen Sie einmal die beiden Ansichten!
Das dritte Kästchen ermöglicht das Einblenden des Clusterings. Damit dieses aber erscheinen kann, muss es mit der Visualisierung Clustering zuerst vorgenommen werden. Die einzelnen Cluster werden in unterschiedlichen Farben dargestellt. Diese Clasterfarben werden auch für die zwei weiteren Visualisierungen "Korrespondenz" und "Ordination" übernommen. Ist ein Datenpunkt in schwarz-, weiss- oder grauer Farbe angezeigt, bedeutet dies, dass er keinem Cluster zugeordnet wurde, oder genauer: dass er ein eigenes Cluster bildet. Genaueres lesen Sie bitte in der Visualisierung Clustering nach.
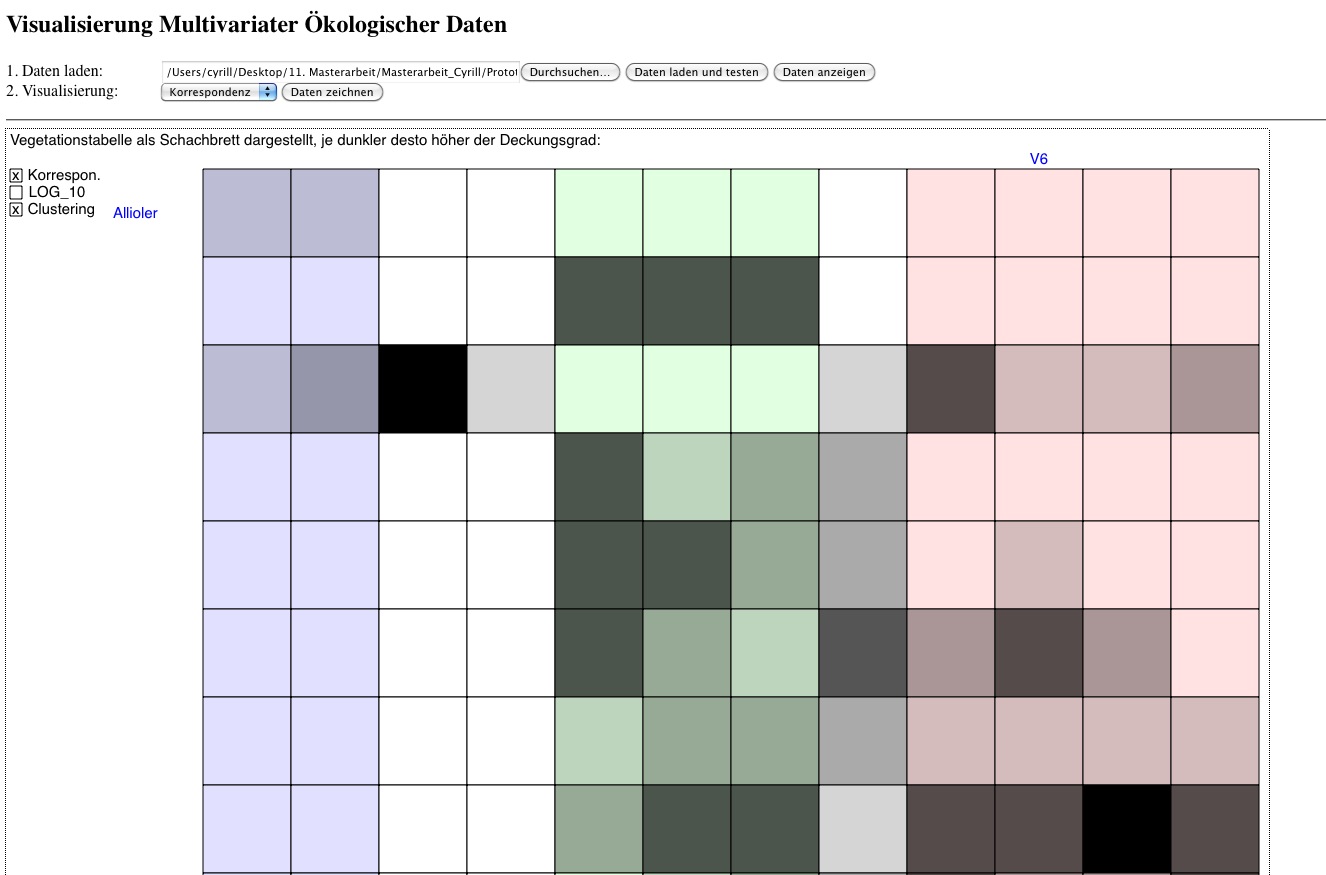
Abbildung 2: Visualisierung der Korrespondenz, d.h. der korrespondierenden Arten und Vegetationsaufnahmen. In Farbe ist das aktuelle Clustering dargestellt.
- Clustering
3.1 Visualisierung
Wenn Sie die Visualisierung "Clustering" wählen (Abb. 3), werden Ihre Vegetationsaufnahmen in einem ähnlichen Schachbrettmuster dargestellt, wie Sie es schon von der Visualisierung "Korrespondenz" kennen. Hier werden nun aber Unterschiede zwischen ganzen Vegetationsaufnahmen dargestellt. Je unterschiedlicher zwei Vegetationsaufnahmen sind, desto dunkler wird die Kombination der beiden Vegetationsaufnahmen im Schachbrett dargestellt. Eine derartige Darstellung wird Distanz- oder einfach Dreiecksmatrix genannt. Sie gibt für alle möglichen Zweierkombinationen von Vegetationsaufnahmen ein Mass an Unterschiedlichkeit dieser beiden Vegetationsaufnahmen an. Distanz bedeutet also Unterschiedlichkeit oder Differenz zwischen Vegetationsaufnahmen und stammt aus dem Gedankengut der Ordination.Fahren Sie mit der Maus über das Schachbrett und achten Sie auf die Zeilen- und Spaltenköpfe. Sie werden feststellen, dass Sie Ihre Arten als Zeilenkopf in dieser Visualisierung nicht mehr finden können. Stattdessen finden Sie sowohl im Spalten- wie auch im Zeilenkopf die Namen Ihrer Vegetationsaufnahmen. Jedes Feld des Schachbretts gibt also den Unterschied zwischen zwei Vegetationsaufnahmen wider. Diese sogenannte Distanz beruht dabei auf Unterschieden bezüglich den Deckungsgraden der jeweils vorhandenen Arten der beiden verglichenen Vegetationsaufnahmen. Es gibt in der Vegetationsökologie verschiedene Distanzmasse, welche gebräuchlich sind. Das heisst, es gibt verschiedene Möglichkeiten die Distanz zwischen zwei Vegetationsaufnahmen zu berechnen. In dieser Visualisierung wird der Bray-Curtis-Koeffizient verwendet. Die Diagonale des Schachbrettes entspricht dabei dem Vergleich einer Vegetationsaufnahme mit sich selber. Sie ist deshalb blau markiert und weisst immer einen Wert von Null auf.

Abbildung 3: Visualisierung des Clusterings. Die aktuellen Cluster sind in weichen Farbe dargestellt. Der Schieberegler ermöglicht engere oder weitere Clusterbildung.
3.2 Interaktivität
Klicken Sie irgendwo auf das Schachbrett (Abb. 3), und lassen Sie sich dadurch den Bray-Curtis-Koeffizient anzeigen. Fahren Sie mit dem Mauszeiger über das Schachbrett und lassen Sie sich so die Bray-Curtis-Distanz zwischen jeweils zwei Vegetationsaufnahmen anzeigen. Der angezeigte Koeffizient stimmt mit den Grautönen des Schachbrettmusters überein: Je grösser der Koeffizient, desto grösser der Unterschied zwischen den beiden verglichenen Vegetationsaufnahmen und desto dunkler das entsprechende Feld. Klicken Sie erneut auf das Schachbrett, verschwindet die Anzeige wieder.Wenn Sie das Kästchen "Clustering" anwählen, werden einige hellere Felder des Schachbretts in Farbe dargestellt (Abb. 3). Eine Farbe entspricht dabei jeweils einem Cluster. Klicken Sie erneut auf das Kästchen "Clustering" verschwinden die Clustering-Farben wieder. Ein Cluster ist eine Gruppe von Vegetationsaufnahmen, welche untereinander ähnlich sind. Wir versuchen also Vegetationsaufnahmen sinnvoll zu gruppieren. Mit dem Schieberegler können Sie vorgeben, wie gross die Bray-Curtis-Distanz maximal sein darf, damit zwei Vegetationsaufnahmen noch in dasselbe Cluster aufgenommen werden. Die angefärbten Felder weisen deshalb meist (nicht immer, lesen Sie dazu das Nearest-neighbour-Clustering-Verfahren) eine geringere Bray-Curtis-Distanz auf, als im blauen Schieberegler voreingestellt ist. Damit werden die beiden verglichenen Vegetationsaufnahmen zu einem Cluster zusammengefasst und mit einer gemeinsamen Farbe markiert. Gibt es weitere Vegetationsaufnahmen, welche demselben Cluster angehören, werden auch diese mit derselben Farbe dargestellt.
Spielen Sie nun mit dem Schieberegler (Abb. 3) durch einen Klick auf die gewünschte Stelle innerhalb des Reglers. Die vorgegebene, maximale Distanz zur Clusterbildung ist unterhalb des Schiebereglers in blauer Farbe angegeben und verändert sich mit dem Verschieben des Reglers. Schieben Sie den Regler nach links, wird die Clustering-Distanz immer kleiner. Jetzt müssen zwei Vegetationsaufnahmen sehr ähnlich sein, damit sie in dasselbe Cluster aufgenommen werden. Es können sich dadurch anfänglich mehrere, kleine Cluster bilden. Die vorgegebene Distanz kann aber auch so klein werden, dass die Anzahl der Cluster zurückgeht bis keine Cluster mehr vorhanden sind. In diesem Fall weisen alle Vegetationsaufnahmen grössere Bray-Curtis-Distanzen zueinander auf als die Distanz, welche mit dem Schieberegler vorgegeben wurde. Damit erscheint das ganze Schachbrett in Grautönen. Schieben Sie den Regler wieder nach rechts, wird die vorgegebene Clustering-Distanz wieder grösser und es beginnen sich erneut Clusters zu bilden. Ist die vorgegebene Clustering-Distanz sehr gross, kann es dazu kommen, dass alle Vegetationsaufnahmen in ein einziges Cluster aufgenommen werden. In diesem Fall erscheint das gesamte Schachbrett ausser der Diagonale in einer Farbe.
3.3 Statistisch- und technischer Hintergrund
Wer sich die Schachbrett-Visualisierung anschaut, erkennt, dass die dargestellte Matrix an der Diagonale gespiegelt ist (Abb. 3). Das obere rechte Dreieck entspricht dem unteren linken Dreieck. Diese Matrix wird auch als Distanz-, Unähnlichkeits- oder einfach Dreiecksmatrix (triangular matrix) bezeichnet (Leyer, 2007:53). Die Diagonale entspricht dabei dem Vergleich einer Vegetationsaufnahme mit sich selber. Hier liegt der Bray-Curtis-Koeffizient folglich immer bei Null. Der Vergleich einer Vegetationsaufnahme mit sich selber ist natürlich uninteressant, weshalb die Diagonale auch blau hervorgehoben erscheint.Zur Berechnung des Unterschiedes oder des sogenannten Distanzmasses zwischen zwei Vegetationsaufnahmen wird der Bray-Curtis-Unähnlichkeits-Koeffizient verwendet (Bray & Curtis 1957). Dieser wird in weiten Bereichen der Ökologie zur Berechnung von Unähnlichkeiten zwischen zwei Vegetationsaufnahmen verwendet und ist von fundamentaler Bedeutung für ökologische Fragestellungen (Leyer, 2007). Er spannt ein Intervall von Null bis Eins auf, indem er ein Verhältnis zwischen gemeinsamen und nicht gemeinsamen Arten zweier Vegetationsaufnahmen aufzeigt. Seine Berechnung erfolgt nach:
Dbc = 1 - Sbc und Sbc = 2w/(B+C).
Wobei:
Dbc für "Dissimilarity" nach "bray-curtis", also für den Bray-Curtis-Unähnlichkeits-Koeffizient;
Sbc für "Similarity" nach "bray-curtis", also für den Bray-Curtis-Ähnlichkeits-Koeffizient;
B für die Summe der Deckungen in der einen Vegetationsaufnahme;
C für die Summe der Deckungen in der anderen Vegetationsaufnahme sowie
w für die Summe der jeweils niedrigeren Deckung einer Art in den beiden verglichenen Vegetationsaufnahmen über alle Arten steht. (Leyer, 2007:49)
Das verwendete Clusteringverfahren ist das Nearest-neighbour-Verfahren (Leyer, 2007:160). Das führt dazu, dass über Kettenbildung auch zwei weiter entfernte Vegetationsaufnahmen in dasselbe Cluster gelangen können. Dies ist immer dann der Fall, wenn zwischen zwei Vegetationsaufnahmen eine weitere Vegetationsaufnahmen liegt, die zu den beiden anderen eine geringere Distanz, als der Schieberegler festlegt, aufweist. Damit ist es möglich, dass zwei Vegetationsaufnahmen in dasselbe Cluster aufgenommen werden, obwohl ihre Distanz grösser ist als jene, welche mit dem Schieberegler vorgegeben wird.
- Ordination
4.1 Visualisierung
Es gibt viele verschiedene Ordinationsverfahren. Alle haben ein gemeinsames Ziel: Die Reduktion von multivariaten, also multidimensionalen Daten auf wenige Dimensionen. Es findet also eine sogenannte Dimensionsreduktion statt. Die Ordination ist damit eine völlig andere Visualisierungsart Ihrer Daten, da sie gewisse Informationen schlicht nicht berücksichtigt. Konkret werden Ihre Vegetationsaufnahmen als Punkte im zweidimensionalen Raum dargestellt, obwohl sie eigentlich multivariat, also hochdimensional sind. Sie sehen zwei Achsen und Punkte (Abb. 4). Jeder Punkt entspricht dabei einer Vegetationsaufnahme. Die Abstände zwischen den Punkten visualisieren die Unähnlichkeit oder Distanz zwischen den Vegetationsaufnahmen möglichst realitätsgetreu. Ähnliche Vegetationsaufnahmen werden also nahe beieinander gezeichnet, während unterschiedliche Vegetationsaufnahmen weiter voneinander entfernt zu liegen kommen. Sie sehen also sofort, welche Vegetationsaufnahmen ähnlich sind und welche nicht. Dabei müssen Sie aber im Hinterkopf behalten, dass viele Dimensionen wenig oder gar nicht berücksichtig sind. Die Anordnung der Punkte im zweidimensionalen Raum entspricht somit nicht der viel komplexeren, hochdimensionalen Realität. Die Abstände könnten im zweidimensionalen Raum verzerrt oder gar falsch dargestellt werden.Die Visualisierung "Ordination" unterscheidet zwei Farbgebungen. Einmal ohne und einmal mit Clustering. Der Normalfall ist die Ansicht ohne Clustering. Dabei sind zwei Punkte satt blau, zwei satt rot und die restlichen schwarz zu sehen (Abb. 5). Die roten und blauen Punkte zeigen in diesem Fall die vier Pole der hier verwendeten polaren Ordination (Bray & Curtis 1957) an. Die zweite, interessantere Ansicht ist nur möglich, wenn bereits ein Clustering vollzogen wurde und zusätzlich das Kästchen "Clustering" markiert ist. Jetzt sehen Sie etliche Punkte in verschiedenen, weichen Farben (Abb. 4). Dabei entspricht jede Farbe einem Cluster, also einer Gruppen von Vegetationsaufnahmen. Sind einige Punkte trotz Clustering schwarz geblieben, bilden diese alleine ein Cluster.
Die Punkte eines Clusters sollten, müssen aber nicht zwingend, nahe beieinander liegen. Clustering und Ordination sind zwei unterschiedliche Analyseverfahren für multivariate ökologische Daten. In dieser Visualisierung können Sie nun erkennen, ob die beiden Verfahren sinnvolle, d.h. ähnliche Resultate liefern. Liegen gleich gefärbte Punkte nahe beieinander, hat das Clustering (Farben) und die Ordination (Verteilung der Punkte im zweidimensionalen Raum) ähnliche Resultate geliefert. Damit können Sie davon ausgehen, dass Ihre Resultate sinnvoll sind. Sind hingegen Punkte mit unterschiedlicher Farbe nahe beieinander, muss davon ausgegangen werden, dass wenig sinnvolle Resultate vorliegen. Dies bedeutet, dass entweder das Clustering durch Kettenbildung ungeschickte Gruppen bildete oder die Ordination bei der Dimensionsreduktion wichtige Informationen verloren hat (Kindt & Coe, 2005, S. 182).
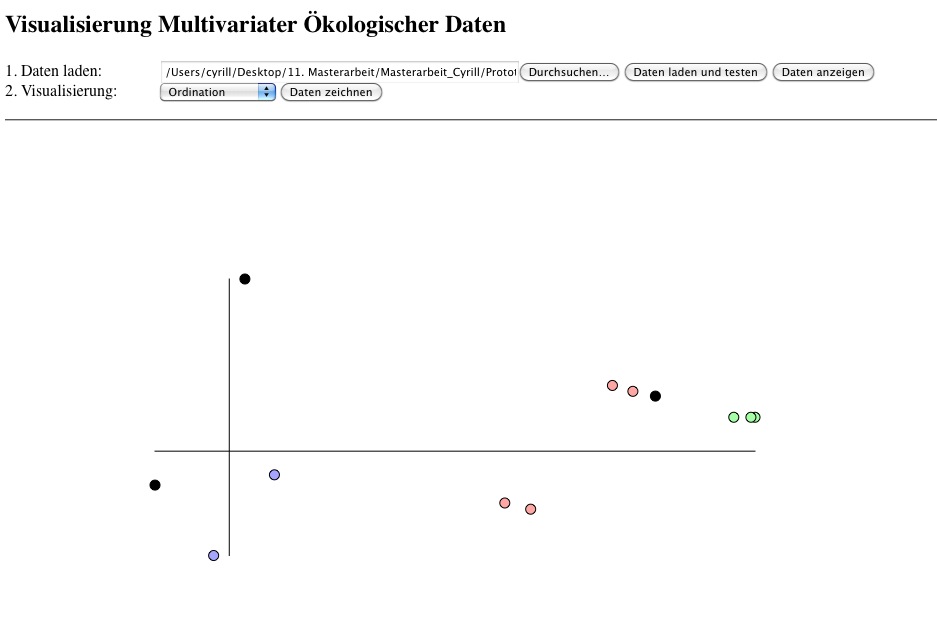
Abbildung 4: Visualisierung der polaren Ordination. Die aktuellen Cluster sind in weichen Farbe dargestellt.
4.2 Interaktivität
Haben Sie Ihre Daten in der Visualisierung "Ordination" gezeichnet, werden Ihre Vegetationsaufnahmen als Punkte im zweidimensionalen Raum dargestellt (Abb. 4). Sie können mit der Maus über die einzelnen Punkte fahren, um sich den Namen der jeweiligen Vegetationsaufnahme anzeigen zu lassen. Durch Klicken auf das Kästchen "Clustering" können Sie gruppierte Vegetationsaufnahmen, sogenannte Cluster einfärben. Diese Möglichkeit setzt allerdings voraus, dass Sie Ihre Daten in der Visualisierung Clustering bereits gruppiert haben. Klicken Sie erneut auf das Kästchen, verschwindet das Clustering wieder. Erscheint Ihnen die Gruppierung nicht einleuchtend, wechseln Sie in die Visualisierung Clustering. Dort können Sie durch Verstellen des Schiebereglers die vorgegebene Clustering-Distanz verändern und dadurch eine neue Gruppierung erreichen (Abb. 3). Jetzt können Sie wieder zurück in die Visualisierung "Ordination" wechseln und sich die neue Gruppierung auch als Ordination ansehen. Viel Spass!4.3 Statistisch- und technischer Hintergrund
Als Ordinationen werden eine ganze Fülle von meist komplexen, mathematischen Verfahren bezeichnet, denen eine grafische Darstellung von Daten in einem Koordinatensystem gemeinsam ist (Leyer, 2007:57). Konkret heisst das, wir bilden unsere Vegetationsaufnahmen in einem sogenannten Artenraum ab. Der Artenraum ist hochdimensional, da jede gefundene Art eine eigene Variable ist und damit eine eigene Dimension erhält. Haben wir also in einer ökologischen Studie neun verschiedene Arten gefunden, ist unser Artenraum 9-dimensional. (Hier ist die Zahl Neun gewählt, da die dargestellte Vegetationstabelle neun verschiedene Arten beinhaltet. Im Normalfall handelt es sich aber oft um hundert oder mehr Arten). Nun können wir uns für jede Vegetationsaufnahme einen Punkt in diesem 9-dimensionalen Raum vorstellen. Wir erhalten also eine Punktwolke im hochdimensionalen Raum. Dabei entsprechen die einzelnen Vektorkomponenten des Ortsvektors eines Punktes den Deckungen der Arten der entsprechenden Vegetationsaufnahme. Der Ortsvektor jeder dargestellten Vegetationsaufnahme kann also direkt aus der Vegetationstabelle herausgelesen werden. Er entspricht jeweils den Deckungen, welche in der Spalte unterhalb der jeweiligen Vegetationsaufnahme zu finden sind. In diesem hochdimensionalen Raum kann nun die Distanz, genauer die Euklidische Distanz, zwischen zwei Vegetationsaufnahmen mit schlichter Trigonometrie berechnet werden. Dieses Distanzmass findet anstelle des Bray-Curtis-Koeffizient Verwendung.Das räumliche Vorstellungsvermögen der meisten Menschen ist jedoch auf drei Dimensionen beschränkt. Auch Visualisierungen von vier und mehr Dimensionen wie "Bio Heat Maps" oder "Parallel Coordinates Charts" wie sie bei Google Charts zu finden sind, werden bei vielen Dimensionen schnell unübersichtlich. Das Ordinationsverfahrens sucht hingegen eine Projektion des hochdimensionalen Raumes auf zwei oder drei Dimensionen mit möglichst geringem Informationsverlust. Diese Projektionen sind übersichtlich, leicht verständlich und schell erfassbar, beinhalten jedoch immer eine Dimensionsreduktion. Diese kommt als Kehrseite der Medaille einem Informationsverlust gleich. Der Informationsverlust soll jedoch möglichst nur redundante, also doppelt vorkommende, oder sonst unwichtige Information betreffen.
Zur Reduktion der eingegebenen multivariaten Daten auf zwei Dimensionen ist hier die sogenannte polare Ordination (Bray & Curtis 1957) zur Anwendung gekommen. Diese ist sehr simpel und hat fast nur noch historische Bedeutung (Leyer 2007:61). Der grosse Vorteil und der Grund für die Wahl dieses Ordinationsverfahren ist ihre Einfachheit. Dadurch kann online über den Webbrowser eine Ordination rasch und ohne allzu grossen Rechenaufwand visualisiert werden. Bei der polaren Ordination werden zuerst zwei möglichst weit voneinander entfernte Datenpunkte (hier Vegetationsaufnahmen) als Endpunkte (Pole) festgelegt. Diese spannen die erste Ordinationsachse (erste Dimension) auf und sind in der Visualisierung als satte rote Punkte gekennzeichnet, sofern das Kästchen "Clustering" nicht angewählt wurde (Abb. 5). Alle weiteren Vegetationsaufnahmen werden auf diese Achse projiziert. Das genaue Verfahren der Projektion ist im Buch "Multivariate Statistik der Ökologie" (Leyer 2007:61) beschrieben. Nun werden zwei weitere Punkte gesucht, welche als Pole die zweite Ordinationsachse (zweite Dimension) aufspannen. Sie sind in der Visualisierung mit einer satten blauen Farbe dargestellt (Abb. 5). Diese zwei weiteren Pole sollen projiziert auf die erste Achse möglichst nahe beieinander liegen, in Tat und Wahrheit, d.h. im hochdimensionalen Raum, aber eine grosse Distanz zueinander aufweisen. Dies garantiert, dass die zweite Achse eine andere Richtung als die erste aufweist und eine weitere grosse Ausdehnung der Punktwolke abdeckt. Alle Vegetationsaufnahmen, das heisst auch die Pole der ersten Achse, werden nun auf diese zweite Achse projiziert. Damit erhält jede Vegetationsaufnahme zwei Werte, einen Wert bezüglich der ersten Ordinationsachse und einen weiteren Wert bezüglich der zweiten Ordinationsachse. Diese beiden Werte kann man sich auch als x- und y-Wert eines gewöhnlichen Koordinatensystems vorstellen. Unser Ziel ist erreicht, wir haben unseren hochdimensionalen Raum auf diese beiden Dimensionen (Ordinationsachsen) reduziert und können unsere multivariaten Vegetationsaufnahmen (Punkte) in nur zwei Dimensionen visualisieren. Diese beiden Dimensionen kann man sich auch als Achsen im hochdimensionalen Raum vorstellen. Wobei deren Lage möglichst so gewählt wurde, dass sie entlang einer möglichst grossen Ausdehnung der Punktwolke zu liegen kommen. Gleichzeitig sollen sich ihre Richtungen möglichst stark unterscheiden. Alle Punkte wurden auf jede der beiden Achsen projiziert und damit die multidimensionale Punktwolke auf zwei Dimensionen reduziert. Wer sich für die polare Ordination interessiert, findet weitere Informationen in Englischer Sprache unter http://ordination.okstate.edu oder in Deutscher Sprache im Buch "Multivariate Statistik der Ökologie" (Leyer 2007:61).

Abbildung 5: Visualisierung der polaren Ordination. Die vier Pole der Ordination sind in sattem Rot oder Blau dargestellt.
- Dateneingabe:
Um eine Visualisierung vornehmen zu können, sind Daten notwendig. Um sich aber nur einmal die Visualisierungsmöglichkeiten anzusehen, ohne eigene Daten hochladen zu müssen, können Sie direkt eine Visualisierung wählen und auf "Daten zeichnen" klicken. Jetzt werden Ihnen vorgegebene Daten angezeigt. Diese Daten entsprechen dieser Art-Aufnahme-Matrix.
In Kürze:
-Strukturieren Sie Ihre Daten in Form einer Art-Aufnahme-Matrix
-Laden Sie Ihre Daten als CSV-Datei hoch.
-Jede Zeile muss mit einem Zeilenumschlag schliessen.
-Jedes Datenelement muss vom folgenden mit einem Komma, Strichpunkt oder Tabulator getrennt werden.
-Das allererste Datenelement bleibt leer!
-Falls Ihre Vegetationstabelle grösser als 30 Zeilen x 30 Spalten gross ist, müssen Sie je nach Visualisierung mit längeren Rechenzeiten von mehreren Sekunden rechnen.
-Je nach Rechenzeit werden Sie vom Browser gefragt, ob Sie das Skript weiter ausführen wollen. Klicken Sie auf "weiter" falls Sie die Visualisierung durchführen wollen.
Etwas ausführlicher:
Alle Daten müssen in einem klar definierten Format in die Webseite eingegeben werden. Stimmt das Format der eingegebenen Datei nicht, erhalten Sie eine rote Rückmeldung zum gefundenen Formatfehler. Eine Art-Aufnahme-Matrix entspricht der Matrix einer Vegetationstabelle: In jeder Zeile eine Art, in jeder Spalte eine Aufnahme. Der Zeilenkopf enthält also den Artnamen und der Spaltenkopf den Namen oder die Nummer der Vegetationsaufnahme. Die restlichen Datenelemente enthalten die Deckungsgrade der einzelnen Arten in den einzelnen Vegetationsaufnahmen in Form einer Zahl. Die Deckung kann zum Beispiel mit Hilfe der Londo-Skala (Leyer 2007:40) oder einem einfachen Prozentwert angegeben werden. Vegetationsaufnahmen nach Braun-Blanquet müssen in die Londo-Skala transformiert werden. Alle Daten werden als CSV-Datei verarbeitet. Eine CSV-Datei (Dateiendung: .txt oder .csv) ist eine Datei, deren einzelne Datenelemente durch Kommata oder Strichpunkt getrennt werden. Eine derartige Datei können Sie mit Excel ganz leicht erstellen oder Sie können die Daten mit einem Texteditor als CSV-Datei erfassen. Jede Zeile der CSV-Datei muss mit einer Zeilenschaltung (Returntaste), das heisst mit einem Carriage Return (\r) oder Line Feed (\n), schliessen. Jedes Datenelement muss vom folgenden mit einem Komma (,) Strichpunkt (;) oder Tabulator (\t) getrennt werden. Das allererste Datenelement (erste Zelle oben links in der Tabelle) bleibt leer, das heisst Ihre Datei beginnt also mit einem Trennungszeichen! Innerhalb eines Datenelementes müssen Dezimalzahlen unbedingt mit einem Punkt geschrieben werden! Wenn Sie Kommata verwenden wird das Programm dies als Ende des Datenelementes interpretieren! Die erste Zeile und die erste Spalte sind für die Namen der Arten und Vegetationsaufnahmen reserviert, diese dürfen Buchstaben und Zahlen enthalten. Alle weiteren Datenelemente in der Tabelle müssen eine positive Zahl beinhalten, da Vegetationstabellen den Deckungsgrad oder die Abundanz von Arten beinhalten und diese grundsätzlich nicht negativ sein können! Negative Zahlen, zum Beispiel von Umweltvariablen, können nicht verarbeitet werden.
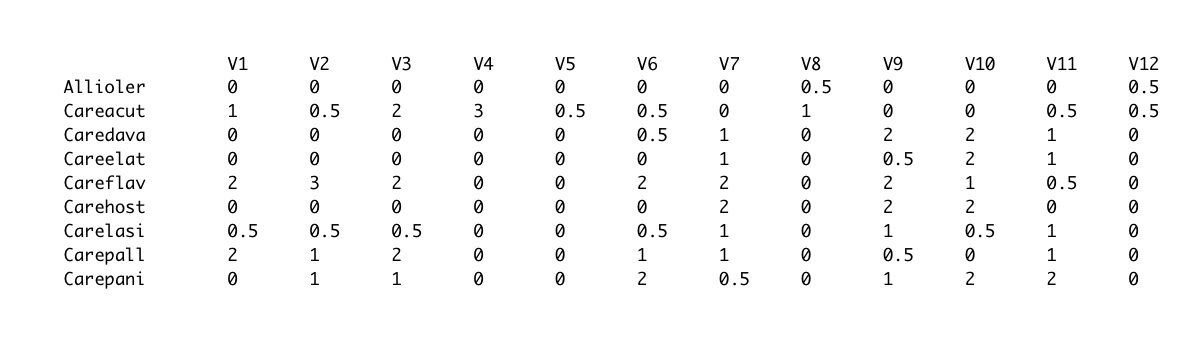
Abbildung 6: Vegetationstabelle oder Art-Aufnahme-Matrix
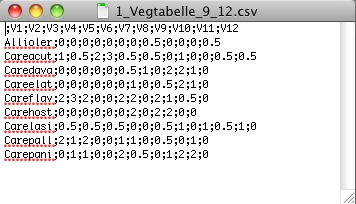
Abbildung 7: CSV-Datei im Text Editor TextEdit dargestellt. Beachten Sie: Die Tabelle beginnt mit einem Strichpunkt (Trennungszeichen).
- Daten mit Hilfe von Excel eingeben
Alle Bilder und Angaben beruhen auf Excel 2011 für Mac Version 14.1.3.
In Kürze:
-Geben Sie Ihre Daten als Art-Aufnahme-Matrix in Excel ein.
-Wählen Sie bei "Speichern unter" das Dateiformat "Tabstoppgetrennter Text (.txt)" oder "Windows-kommagetrennt (.csv)" aus.
-Die dabei entstandene Datei können Sie nun über "Durchsuchen..." mit der Webseite visualisieren.
Etwas ausführlicher:
Um möglichst rasch und einfach Daten zu visualisieren, empfiehlt es sich, diese in Excel zu erfassen. Dabei bleibt die oberste, linke Zelle leer. Die nach rechts folgenden Zellen in der obersten Zeile dienen als Spaltenköpfe. In diese werden die Namen oder Nummern der Vegetationsaufnahmen eingegeben. Die von der obersten, linken Zelle in der ersten Spalte nach unten folgenden Zellen dienen als Zeilenköpfe. In diese werden die Namen der gefundenen Arten eingetragen. Alle weiteren Elemente der Tabelle enthalten nun die Deckungsgrade oder Abundanzen der Arten. Diese Elemente werden in Form einer Dezimalzahl eingegeben, wobei die Dezimalstellen mit einem Punkt abzutrennen sind. Speichern Sie Ihre vollständig erfasste Tabelle im Dateiformat "Tabstoppgetrennter Text (.txt)" oder "Windows-kommagetrennt (.csv)" auf dem Desktop. Möglicherweise frägt Sie Excel, ob Sie wirklich dieses Dateiformat wünschen, da gewisse Excel-Funktionen dadurch verloren gehen. Klicken Sie auf "Weiter". Sie möchten ja trotz diesen Funktionsverlusten eine CSV-Datei erhalten. Diese Datei kann nun direkt mit der Webseite verarbeitet werden. Wechseln Sie zur Webseite, klicken Sie auf "Durchsuchen..." und suchen Sie Ihre Datei auf dem Desktop. Wählen Sie Ihre Datei an und klicken Sie auf "öffnen". Klicken Sie auf "Daten laden und testen". Nun erhalten Sie eine Rückmeldung zu Ihren Daten. Falls ein Fehler vorliegt, wird dieser in roter Schrift angezeigt. Ansonsten erhalten Sie die Rückmeldung "Ihre Daten können gezeichnet werden" in schwarzer Schrift, und Sie können die gewünschte Visualisierung auswählen und mit "Daten zeichnen" anzeigen lassen.
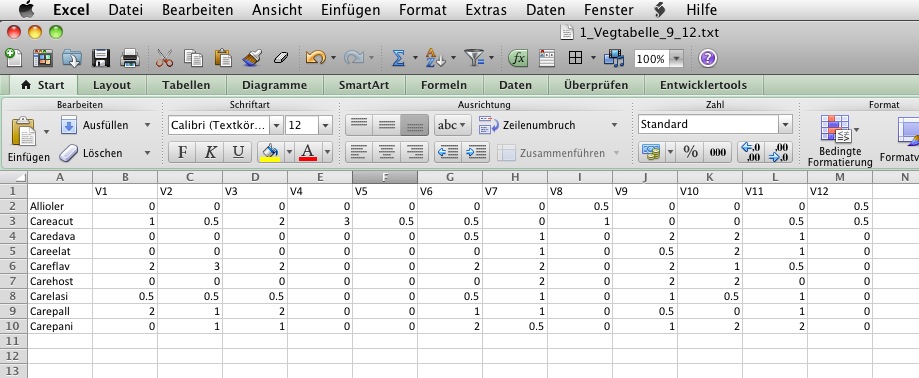
Abbildung 8: In Excel eingegebene Vegetationstabelle
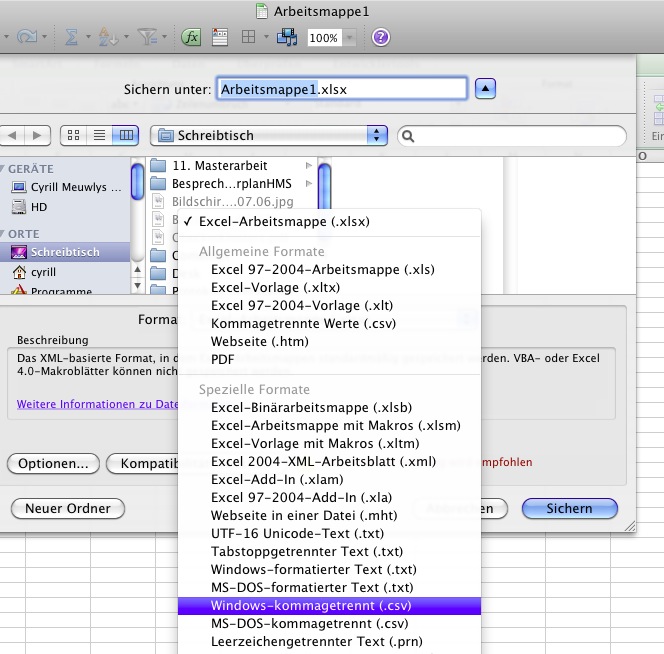
Abbildung 9: Speichern der Excel Datei im CSV-Format. Als Alternative kommt "Tabstoppgetrennter Text (.txt)" ebenso in Frage
- Datenformate: Mögliche Fehler
Die wichtigsten Formatfehler können von der Visualisierung erkannt werden und führen zu einer Rückmeldung in roter Schrift. Die Rückmeldungen sind möglichst verständlich gehalten. Falls trotzdem Unklarheiten auftauchen, können Sie sich im Folgenden näher informieren.
Rückmeldung 1: Das erste verwendete Zeichen sollte ein Trennungszeichen (=Komma, Strichpunkt oder Tabulator) sein...
Auf Grund der Darstellung als Art-Aufnahme-Matrix geht die Visualisierung davon aus, dass das allererste verwendete Zeichen ein Trennungszeichen (=Komma, Strichpunkt oder Tabulator) ist. Ist dies nicht der Fall, muss von einem Fehler oder einer falschen Darstellungsweise ausgegangen werden. Aus der Rückmeldung können Sie zusätzlich das falsche erste Zeichen Ihrer Daten entnehmen. Dies hilft Ihnen womöglich, den Fehler zu beheben.Rückmeldung 2: Ihre Datei enthält keine Zeilenschaltungen...

Abbildung 10: In dieser CSV-Datei sind die Zeilenschaltungen durch ein "¶" gekennzeichnet.
Rückmeldung 3: Die Zeile "i" Ihrer eingegebenen Datei enthält keine Trennungszeichen...
Rückmeldung 4: Nicht alle Zeilen enthalten dieselbe Anzahl Einträge...
Rückmeldung 5: In der "j." Spalte der "i." Zeile Ihrer Vegetationstabelle befindet sich der Zelleninhalt: "Zelleninhalt". Dies wird als negative Zahl interpretiert!...
Rückmeldung 6: In der "j." Spalte der "i." Zeile Ihrer Vegetationstabelle befindet sich der Inhalt: "Zelleninhalt". Ein nicht numerisches Zeichen kann nicht als eine Zahl interpretiert werden...
Rückmeldung 7: In der "j." Spalte der "i." Zeile Ihrer Vegetationstabelle befindet sich der Inhalt: "Zelleninhalt". Dies sind zu viele Punkte...